Difference between revisions of "Talks/Poetics of Research"
m (Text replacement - "monoskop.multiplace.org" to "monoskop.org") |
|||
| (7 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
''An unedited version of a talk given at the conference [http://www.wkv-stuttgart.de/en/program/2014/events/public-library/ Public Library] held at Württembergischer Kunstverein Stuttgart, 1 November 2014.'' | ''An unedited version of a talk given at the conference [http://www.wkv-stuttgart.de/en/program/2014/events/public-library/ Public Library] held at Württembergischer Kunstverein Stuttgart, 1 November 2014.'' | ||
| + | |||
| + | ''Bracketed sequences are to be reformulated.'' | ||
; Poetics of Research | ; Poetics of Research | ||
| Line 47: | Line 49: | ||
Not much has changed in the way how dictionaries constitute order. Selected archives of statements are queried to yield occurrences of particular words, various ''criteria[indicators]'' are applied to filtering and sorting them and in turn the spectrum of [denoted] things allocated in this way is structured into groups and subgroups which are then given, according to other set of rules, shorter or longer names. These constitute facets of [potential] meanings of a word. | Not much has changed in the way how dictionaries constitute order. Selected archives of statements are queried to yield occurrences of particular words, various ''criteria[indicators]'' are applied to filtering and sorting them and in turn the spectrum of [denoted] things allocated in this way is structured into groups and subgroups which are then given, according to other set of rules, shorter or longer names. These constitute facets of [potential] meanings of a word. | ||
| − | So there are at least ''four'' sets of conditions [structuring] dictionaries. One is required to delimit an archive[corpus of texts], one to select and give preference[weights] to occurrences of a word, another to cluster them, and yet another to abstract[generalize] the subject-matter of each of these clusters. Needless to say, this is a craft of a few and these criteria are rarely being disclosed, despite their impact on research, and more generally, their influence as conditions for production[making] of a so called | + | So there are at least ''four'' sets of conditions [structuring] dictionaries. One is required to delimit an archive[corpus of texts], one to select and give preference[weights] to occurrences of a word, another to cluster them, and yet another to abstract[generalize] the subject-matter of each of these clusters. Needless to say, this is a craft of a few and these criteria are rarely being disclosed, despite their impact on research, and more generally, their influence as conditions for production[making] of a so called ''common sense''. |
It doesn't take that much to reimagine what a dictionary is and what it could be, especially having large specialized corpora of texts at hand. These can also serve as aids in production of new words and new meanings. | It doesn't take that much to reimagine what a dictionary is and what it could be, especially having large specialized corpora of texts at hand. These can also serve as aids in production of new words and new meanings. | ||
| Line 62: | Line 64: | ||
Another ''formalized'' and [internalized] process being at play when figuring out a word is its [containment]. Word is not only structured by way of things it potentially denotes but also by words it is potentially part of and those it contains. | Another ''formalized'' and [internalized] process being at play when figuring out a word is its [containment]. Word is not only structured by way of things it potentially denotes but also by words it is potentially part of and those it contains. | ||
| − | The fuzz around categorization of knowledge ''and'' the world in the Western thought can be traced back to Porphyry, if not further. In his introduction to Aristotle's ''Categories'' this 3rd century AD Neoplatonist began expanding the notions of genus and species into their hypothetic consequences. Aristotle's brief work outlines ten categories of 'things that are said' (legomena, λεγόμενα), namely substance (or substantive, {not the same as matter!}, οὐσία), quantity (ποσόν), qualification (ποιόν), a relation (πρός), where (ποῦ), when (πότε), being-in-a-position (κεῖσθαι), having (or state, condition, ἔχειν), doing (ποιεῖν), and being-affected (πάσχειν). In his different work, ''Topics'', Aristotle outlines four kinds of subjects/materials indicated in propositions/problems from which arguments/deductions start. These are a definition (όρος), a genus (γένος), a property (ἴδιος), and an accident (συμβεβηϰόϛ). Porphyry does not explicitly refer ''Topics'', and says he omits speaking "about genera and species, as to whether they subsist (in the nature of things) or in mere conceptions only" [http://www.ccel.org/ccel/pearse/morefathers/files/porphyry_isagogue_02_translation.htm#C1], which means he avoids explicating whether he talks about kinds of concepts or kinds of things in the sensible world. However, the | + | The fuzz around categorization of knowledge ''and'' the world in the Western thought can be traced back to Porphyry, if not further. In his introduction to Aristotle's ''Categories'' this 3rd century AD Neoplatonist began expanding the notions of genus and species into their hypothetic consequences. Aristotle's brief work outlines ten categories of 'things that are said' (legomena, λεγόμενα), namely substance (or substantive, {not the same as matter!}, οὐσία), quantity (ποσόν), qualification (ποιόν), a relation (πρός), where (ποῦ), when (πότε), being-in-a-position (κεῖσθαι), having (or state, condition, ἔχειν), doing (ποιεῖν), and being-affected (πάσχειν). In his different work, ''Topics'', Aristotle outlines four kinds of subjects/materials indicated in propositions/problems from which arguments/deductions start. These are a definition (όρος), a genus (γένος), a property (ἴδιος), and an accident (συμβεβηϰόϛ). Porphyry does not explicitly refer ''Topics'', and says he omits speaking "about genera and species, as to whether they subsist (in the nature of things) or in mere conceptions only" [http://www.ccel.org/ccel/pearse/morefathers/files/porphyry_isagogue_02_translation.htm#C1], which means he avoids explicating whether he talks about kinds of concepts or kinds of things in the sensible world. However, the work sparked confusion, as the following passage [suggests]: |
<blockquote>"[I]n each category there are certain things most generic, and again, others most special, and between the most generic and the most special, others which are alike called both genera and species, but the most generic is that above which there cannot be another superior genus, and the most special that below which there cannot be another inferior species. Between the most generic and the most special, there are others which are alike both genera and species, referred, nevertheless, to different things, but what is stated may become clear in one category. Substance indeed, is itself genus, under this is body, under body animated body, under which is animal, under animal rational animal, under which is man, under man Socrates, Plato, and men particularly." (Owen 1853, [http://www.ccel.org/ccel/pearse/morefathers/files/porphyry_isagogue_02_translation.htm#C2])</blockquote> | <blockquote>"[I]n each category there are certain things most generic, and again, others most special, and between the most generic and the most special, others which are alike called both genera and species, but the most generic is that above which there cannot be another superior genus, and the most special that below which there cannot be another inferior species. Between the most generic and the most special, there are others which are alike both genera and species, referred, nevertheless, to different things, but what is stated may become clear in one category. Substance indeed, is itself genus, under this is body, under body animated body, under which is animal, under animal rational animal, under which is man, under man Socrates, Plato, and men particularly." (Owen 1853, [http://www.ccel.org/ccel/pearse/morefathers/files/porphyry_isagogue_02_translation.htm#C2])</blockquote> | ||
| − | Porphyry took one of Aristotle's ten categories of the word, substance, and dissected it using one of his four rhetorical devices, genus. | + | Porphyry took one of Aristotle's ten categories of the word, substance, and dissected it using one of his four rhetorical devices, genus. Employing Aristotle's categories, genera and species as means for logical operations, for dialectic, Porphyry's interpretation resulted in having more resemblance to the perceived ''structures'' of the world. So they began to bloom. |
There were earlier examples, but Porphyry was the most influential in injecting the ''universalist'' version of classification [implying] the figure of a tree into the [locus] of Aristotle's thought. Knowledge became monotheistic. | There were earlier examples, but Porphyry was the most influential in injecting the ''universalist'' version of classification [implying] the figure of a tree into the [locus] of Aristotle's thought. Knowledge became monotheistic. | ||
| − | Classification schemes [growing from one point] play a major role in untangling the format of modern encyclopedia from that of the dictionary governed by alphabet. Two of the most influential encyclopedias of the 18th century are cases in the point. Although still keeping 'dictionary' in their titles, they are conceived not to represent words but knowledge. The [upper-most] genus of the body was set as the body of knowledge. The English ''Cyclopaedia, or an Universal Dictionary of Arts and Sciences'' (1728) splits into two main branches: "natural and scientifical" and "artificial and technical" | + | Classification schemes [growing from one point] play a major role in untangling the format of modern encyclopedia from that of the dictionary governed by alphabet. Two of the most influential encyclopedias of the 18th century are cases in the point. Although still keeping 'dictionary' in their titles, they are conceived not to represent words but knowledge. The [upper-most] genus of the body was set as the body of knowledge. The English ''Cyclopaedia, or an Universal Dictionary of Arts and Sciences'' (1728) splits into two main branches: "natural and scientifical" and "artificial and technical"; these further split down to 47 classes in total, each carrying a structured list (on the following pages) of thematic articles, serving as table of contents. The French ''Encyclopedia: or a Systematic Dictionary of the Sciences, Arts, and Crafts'' (1751) [unwinds] from judgement (''entendement''), branches into memory as history, reason as philosophy, and imagination as poetry. The logic of containers was employed as an aid not only to deal with the enormous task of naming and not omiting anything from what is known, but also for the management of labour of hundreds of writers and researchers, to create a mechanism for delegating work and the distribution of responsibilities. Flesh was also more present, in the field research, with researchers attending workshops and sites of everyday life to annotate it. |
The world came forward to unshine the word in other schemes. Darwin's tree of evolution and some of the modern document classification systems such as Charles A. Cutter's ''Expansive Classification'' (1882) set to classify the world itself and set the field for what has came to be known as authority lists structuring metadata in today's computing. | The world came forward to unshine the word in other schemes. Darwin's tree of evolution and some of the modern document classification systems such as Charles A. Cutter's ''Expansive Classification'' (1882) set to classify the world itself and set the field for what has came to be known as authority lists structuring metadata in today's computing. | ||
| Line 143: | Line 145: | ||
Its role seemingly vanishes in the digital text. But it can be easily transformed. Besides serving as a table of pre-searched results the subject-index also gives a distinct idea about content of the book. Two patterns give us a clue: numbers of occurrences of selected words give subjects weights, while words that seem specific to the book outweights other even if they don't occur very often. A selection of these words then serves as a descriptor of the whole text, and can be thought of as a specific kind of 'tags'. | Its role seemingly vanishes in the digital text. But it can be easily transformed. Besides serving as a table of pre-searched results the subject-index also gives a distinct idea about content of the book. Two patterns give us a clue: numbers of occurrences of selected words give subjects weights, while words that seem specific to the book outweights other even if they don't occur very often. A selection of these words then serves as a descriptor of the whole text, and can be thought of as a specific kind of 'tags'. | ||
| − | This process was formalized in a mathematical function in the 1970s, thanks to a formula by Karen Spärck Jones which she entitled 'inverse document frequency' (IDF), or in other words, "term specificity". It is measured as a proportion of texts in the corpus where the word appears at least once to the total number of texts. When multiplied by the frequency of | + | This process was formalized in a mathematical function in the 1970s, thanks to a formula by Karen Spärck Jones which she entitled 'inverse document frequency' (IDF), or in other words, "term specificity". It is measured as a proportion of texts in the corpus where the word appears at least once to the total number of texts. When multiplied by the frequency of the word ''in'' the text (divided by the maximum frequency of any word in the text), we get ''term frequency-inverse document frequency'' (tf-idf). In this way we can get an automated list of subjects which are particular in the text when compared to a group of texts. |
We came to learn it by practice of searching the web. It is a mechanism not dissimilar to thought process involved in retrieving particular information online. And search engines have it built in their indexing algorithms as well. | We came to learn it by practice of searching the web. It is a mechanism not dissimilar to thought process involved in retrieving particular information online. And search engines have it built in their indexing algorithms as well. | ||
| Line 153: | Line 155: | ||
==Final remarks== | ==Final remarks== | ||
; 1 | ; 1 | ||
| − | New disciplines emerge all the time - most recently, for example, cultural techniques, software studies, or media archaeology. It takes years, even decades, before they gain dedicated shelves in libraries or a category in interlibrary digital repositories. Not that it matters that much. They are not only sites of academic opportunities but, firstly, frameworks of new perspectives of looking at the world, new domains of knowledge. From the perspective of researcher the partaking in a discipline involves negotiating its vocabulary, classifications, corpus, and specific terms[subjects]. Creating new fields involves all that, and more. Even when one goes against all disciplines. | + | New disciplines emerge all the time - most recently, for example, cultural techniques, software studies, or media archaeology. It takes years, even decades, before they gain dedicated shelves in libraries or a category in interlibrary digital repositories. Not that it matters that much. They are not only sites of academic opportunities but, firstly, frameworks of new perspectives of looking at the world, new domains of knowledge. From the perspective of researcher the partaking in a discipline involves negotiating its vocabulary, classifications, corpus, reference field, and specific terms[subjects]. Creating new fields involves all that, and more. Even when one goes against all disciplines. |
; 2 | ; 2 | ||
| Line 165: | Line 167: | ||
* 1. Process the files text.1-5.txt and produce freq.1-5.txt with lists of (nonlemmatized) words (in respective texts), ordered by frequency: | * 1. Process the files text.1-5.txt and produce freq.1-5.txt with lists of (nonlemmatized) words (in respective texts), ordered by frequency: | ||
| − | for i in {1..5}; do tr '[A-Z]' '[a-z]' < text.$i.txt | tr -c '[a-z]' '[\012*]' | tr -d '[:punct:]' | sort | uniq -c | sort -k 1nr | sed '1,1d' > temp.txt; max=$(awk -vvar=1 -F" " 'NR==1 {print $var}' temp.txt); awk -vmaxx=$max -F' ' '{printf "%-7.7f %s\n", $1=0.5+($1/(maxx*2)), $2}' <temp.txt > freq.$i.txt; done && rm temp.txt | + | <blockquote>for i in {1..5}; do tr '[A-Z]' '[a-z]' < text.$i.txt | tr -c '[a-z]' '[\012*]' | tr -d '[:punct:]' | sort | uniq -c | sort -k 1nr | sed '1,1d' > temp.txt; max=$(awk -vvar=1 -F" " 'NR==1 {print $var}' temp.txt); awk -vmaxx=$max -F' ' '{printf "%-7.7f %s\n", $1=0.5+($1/(maxx*2)), $2}' <temp.txt > freq.$i.txt; done && rm temp.txt</blockquote> |
* 2. Process the files freq.1-5.txt and produce tfidf.1-5.txt containing a list of words (out of 500 most frequent in respective lists), ordered by weight (specificity for each text): | * 2. Process the files freq.1-5.txt and produce tfidf.1-5.txt containing a list of words (out of 500 most frequent in respective lists), ordered by weight (specificity for each text): | ||
| − | for j in {1..5}; do rm freq.$j.txt.temp; lines=$(wc -l freq.$j.txt) && for i in {1..500}; do word=$(awk -vline="$i" -vfield=2 -F" " 'NR==line {print $field}' freq.$j.txt); tf=$(awk -vline="$i" -vfield=1 -F" " 'NR==line {print $field}' freq.$j.txt); count=$(egrep -lw $word freq.?.txt | wc -l); idf=$(echo "1+l(5/$count)" | bc -l); tfidf=$(echo $tf*$idf | bc); echo $word $tfidf >> freq.$j.txt.temp; done; sort -k 2nr < freq.$j.txt.temp > tfidf.$j.txt; done | + | <blockquote>for j in {1..5}; do rm freq.$j.txt.temp; lines=$(wc -l freq.$j.txt) && for i in {1..500}; do word=$(awk -vline="$i" -vfield=2 -F" " 'NR==line {print $field}' freq.$j.txt); tf=$(awk -vline="$i" -vfield=1 -F" " 'NR==line {print $field}' freq.$j.txt); count=$(egrep -lw $word freq.?.txt | wc -l); idf=$(echo "1+l(5/$count)" | bc -l); tfidf=$(echo $tf*$idf | bc); echo $word $tfidf >> freq.$j.txt.temp; done; sort -k 2nr < freq.$j.txt.temp > tfidf.$j.txt; done</blockquote> |
* 3. Process the files tfidf.1-5.txt and their source text, text.txt, and produce occ.txt with concordance of top 3 words from each of them: | * 3. Process the files tfidf.1-5.txt and their source text, text.txt, and produce occ.txt with concordance of top 3 words from each of them: | ||
| − | rm occ.txt && for j in {1..5}; do echo "$j" >> occ.txt; ptx -f -w 150 text.txt.$j > occ.$j.txt; for i in {1..3}; do word=$(awk -vline="$i" -vfield=1 -F" " 'NR==line {print $field}' tfidf.$j.txt); egrep -i "[[:alpha:]] $word" occ.$j.txt >> occ.txt; done; done | + | <blockquote>rm occ.txt && for j in {1..5}; do echo "$j" >> occ.txt; ptx -f -w 150 text.txt.$j > occ.$j.txt; for i in {1..3}; do word=$(awk -vline="$i" -vfield=1 -F" " 'NR==line {print $field}' tfidf.$j.txt); egrep -i "[[:alpha:]] $word" occ.$j.txt >> occ.txt; done; done</blockquote> |
Dušan Barok | Dušan Barok | ||
Latest revision as of 19:13, 2 August 2015
An unedited version of a talk given at the conference Public Library held at Württembergischer Kunstverein Stuttgart, 1 November 2014.
Bracketed sequences are to be reformulated.
- Poetics of Research
In this talk I'm going to attempt to identify [particular] cultural algorithms, ie. processes in which cultural practises and software meet. With them a sphere is implied in which algorithms gather to form bodies of practices and in which cultures gather around algorithms. I'm going to approach them through the perspective of my practice as a cultural worker, editor and artist, considering practice in the same rank as theory and poetics, and where theorization of practice can also lead to the identification of poetical devices.
The primary motivation for this talk is an attempt to figure out where do we stand as operators, users [and communities] gathering around infrastructures containing a massive body of text (among other things) and what sort of things might be considered to make a difference [or to keep making difference].
The talk mainly [considers] the role of text and the word in research, by way of several figures.
- A
A reference, list, scheme, table, index; those things that intervene in the flow of narrative, illustrating the point, perhaps in a more economic way than the linear text would do. Yet they don't function as pictures, they are primarily texts, arranged in figures. Their forms have been standardised[normalised] over centuries, withstood the transition to the digital without any significant change, being completely intuitive to the modern reader. Compared to the body of text they are secondary, run parallel to it. Their function is however different to that of the punctuation. They are there neither to shape the narrative nor to aid structuring the argument into logical blocks. Nor is their function spatial, like in visual poems. Their positions within a document are determined according to the sequential order of the text, [standing as attachments] and are there to clarify the nature of relations among elements of the subject-matter, or to establish relations with other documents. The [premise] of my talk is that these textual figures also came to serve as the abstract[relational] models determining possible relations among documents as such, and in consequence [to structure conditions [of research]].
- B
It can be said that research, as inquiry into a subject-matter, consists of discrete queries. A query, such as a question about what something is, what kinds, parts and properties does it have, and so on, can be consulted in existing documents or generate new documents based on collection of data [in] the field and through experiment, before proceeding to reasoning [arguments and deductions]. Formulation of a query is determined by protocols providing access to documents, which means that there is a difference between collecting data outside the archive (the undocumented, ie. in the field and through experiment), consulting with a person--an archivist (expert, librarian, documentalist), and consulting with a database storing documents. The phenomena such as [deepening] of specialization and throughout digitization [have given] privilege to the database as [a|the] [fundamental] means for research. Obviously, this is a very recent [phenomenon]. Queries were once formulated in natural language; now, given the fact that databases are queried [using] SQL language, their interfaces are mere extensions of it and researchers pose their questions by manipulating dropdowns, checkboxes and input boxes mashed together on a flat screen being ran by software that in turn translates them into a long line of conditioned SELECTs and JOINs performed on tables of data.
Specialization, digitization and networking have changed the language of questioning. Inquiry, once attached to the flesh and paper has been [entrusted] to the digital and networked. Researchers are querying the black box.
- C
Searching in a collection of [amassed/assembled] [tangible] documents (ie. bookshelf) is different from searching in a systematically structured repository (library) and even more so from searching in a digital repository (digital library). Not that they are mutually exclusive. One can devise structures and algorithms to search through a printed text, or read books in a library one by one. They are rather [models] [embodying] various [processes] associated with the query. These properties of the query might be called [the sequence], the structure and the index. If they are present in the ways of querying documents, and we will return to this issue, are they persistent within the inquiry as such? [wait]
- D
This question itself is a rupture in the sequence. It makes a demand to depart from one narrative [a continuous flow of words] to another, to figure out, while remaining bound to it [it would be even more as a so-called rhetorical question]. So there has been one sequence, or line, of the inquiry--about the kinds of the query and its properties. That sequence itself is a digression, from within the sequence about what is research and describing its parts (queries). We are thus returning to it and continue with a question whether the properties of the inquiry are the same as the properties of the query.
- E
But isn't it true that every single utterance occurring in a sequence yields a query as well? Let's consider the word utterance. [wait] It can produce a number of associations, for example with how Foucault employs the notion of énoncé in his Archaeology of Knowledge, giving hard time to his English translators wondering whether utterance or statement is more appropriate, or whether they are interchangeable, and what impact would each choice have on his reception in the Anglophone world. Limiting ourselves to textual forms for now (and not translating his work but pursing a different inquiry), let us say the utterance is a word [or a phrase or an idiom] in a sequence such as a sentence, a paragraph, or a document.
(F) The structure[edit]
This distinction is as old as recorded Western thought since both Plato and Aristotle differentiate between a word on its own ("the said", a thing said) and words in the company of other words. For example, Aristotle's Categories [lay] on the [notion] of words on their own, and they are made the subject-matter of that inquiry. [For him], the ambiguity of connotation words [produce] lies in their synonymity, understood differently from the moderns--not as more words denoting a similar thing but rather one word denoting various things. Categories were outlined as a device to differentiate among words according to kinds of these things. Every word as such belonged to not less and not more than one of ten categories.
So it happens to the word utterance, as to any other word uttered in a sequence, that it poses a question, a query about what share of the spectrum of possibly denoted things might yield as the most appropriate in a given context. The more context the more precise share comes to the fore. When taken out of the context ambiguity prevails as the spectrum unveils in its variety.
Thus single words [as any other utterances] are questions, queries, themselves, and by occuring in statements, in context, their [means] are being singled out.
This process is conditioned by what has been formalized as the techniques of regulating definitions of words.
(G) The structure: words as words[edit]

Ephraim Chambers, Cyclopaedia, or an Universal Dictionary of Arts and Sciences, 1728, p. 210. [3]

Detail from the Liddell-Scott Greek-English Lexicon, c1843.



Dictionaries have had a long life. The ancient Greek scholar and poet Philitas of Cos living in the 4th c. BCE wrote a vocabulary explaining the meanings of rare Homeric and other literary words, words from local dialects, and technical terms. The vocabulary, called Disorderly Words (Átaktoi glôssai), has been lost, with a few fragments quoted by later authors. One example is that the word πέλλα (pélla) meant "wine cup" in the ancient Greek region of Boeotia; contrasted to the same word meaning "milk pail" in Homer's Iliad.
Not much has changed in the way how dictionaries constitute order. Selected archives of statements are queried to yield occurrences of particular words, various criteria[indicators] are applied to filtering and sorting them and in turn the spectrum of [denoted] things allocated in this way is structured into groups and subgroups which are then given, according to other set of rules, shorter or longer names. These constitute facets of [potential] meanings of a word.
So there are at least four sets of conditions [structuring] dictionaries. One is required to delimit an archive[corpus of texts], one to select and give preference[weights] to occurrences of a word, another to cluster them, and yet another to abstract[generalize] the subject-matter of each of these clusters. Needless to say, this is a craft of a few and these criteria are rarely being disclosed, despite their impact on research, and more generally, their influence as conditions for production[making] of a so called common sense.
It doesn't take that much to reimagine what a dictionary is and what it could be, especially having large specialized corpora of texts at hand. These can also serve as aids in production of new words and new meanings.
(H) The structure: words as knowledge and the world[edit]
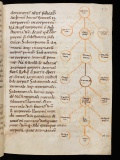
Boethius's rendering of a classification tree described in Porphyry's Isagoge (3th c.), [6th c.] 10th c. [4]

Ephraim Chambers, Cyclopaedia, or an Universal Dictionary of Arts and Sciences, London, 1728, p. II. [5]

Système figuré des connaissances humaines, Encyclopédie ou Dictionnaire raisonné des sciences, des arts et des métiers, 1751. [6]
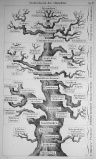
Haeckel - Darwin's tree.




Another formalized and [internalized] process being at play when figuring out a word is its [containment]. Word is not only structured by way of things it potentially denotes but also by words it is potentially part of and those it contains.
The fuzz around categorization of knowledge and the world in the Western thought can be traced back to Porphyry, if not further. In his introduction to Aristotle's Categories this 3rd century AD Neoplatonist began expanding the notions of genus and species into their hypothetic consequences. Aristotle's brief work outlines ten categories of 'things that are said' (legomena, λεγόμενα), namely substance (or substantive, {not the same as matter!}, οὐσία), quantity (ποσόν), qualification (ποιόν), a relation (πρός), where (ποῦ), when (πότε), being-in-a-position (κεῖσθαι), having (or state, condition, ἔχειν), doing (ποιεῖν), and being-affected (πάσχειν). In his different work, Topics, Aristotle outlines four kinds of subjects/materials indicated in propositions/problems from which arguments/deductions start. These are a definition (όρος), a genus (γένος), a property (ἴδιος), and an accident (συμβεβηϰόϛ). Porphyry does not explicitly refer Topics, and says he omits speaking "about genera and species, as to whether they subsist (in the nature of things) or in mere conceptions only" [8], which means he avoids explicating whether he talks about kinds of concepts or kinds of things in the sensible world. However, the work sparked confusion, as the following passage [suggests]:
"[I]n each category there are certain things most generic, and again, others most special, and between the most generic and the most special, others which are alike called both genera and species, but the most generic is that above which there cannot be another superior genus, and the most special that below which there cannot be another inferior species. Between the most generic and the most special, there are others which are alike both genera and species, referred, nevertheless, to different things, but what is stated may become clear in one category. Substance indeed, is itself genus, under this is body, under body animated body, under which is animal, under animal rational animal, under which is man, under man Socrates, Plato, and men particularly." (Owen 1853, [9])
Porphyry took one of Aristotle's ten categories of the word, substance, and dissected it using one of his four rhetorical devices, genus. Employing Aristotle's categories, genera and species as means for logical operations, for dialectic, Porphyry's interpretation resulted in having more resemblance to the perceived structures of the world. So they began to bloom.
There were earlier examples, but Porphyry was the most influential in injecting the universalist version of classification [implying] the figure of a tree into the [locus] of Aristotle's thought. Knowledge became monotheistic.
Classification schemes [growing from one point] play a major role in untangling the format of modern encyclopedia from that of the dictionary governed by alphabet. Two of the most influential encyclopedias of the 18th century are cases in the point. Although still keeping 'dictionary' in their titles, they are conceived not to represent words but knowledge. The [upper-most] genus of the body was set as the body of knowledge. The English Cyclopaedia, or an Universal Dictionary of Arts and Sciences (1728) splits into two main branches: "natural and scientifical" and "artificial and technical"; these further split down to 47 classes in total, each carrying a structured list (on the following pages) of thematic articles, serving as table of contents. The French Encyclopedia: or a Systematic Dictionary of the Sciences, Arts, and Crafts (1751) [unwinds] from judgement (entendement), branches into memory as history, reason as philosophy, and imagination as poetry. The logic of containers was employed as an aid not only to deal with the enormous task of naming and not omiting anything from what is known, but also for the management of labour of hundreds of writers and researchers, to create a mechanism for delegating work and the distribution of responsibilities. Flesh was also more present, in the field research, with researchers attending workshops and sites of everyday life to annotate it.
The world came forward to unshine the word in other schemes. Darwin's tree of evolution and some of the modern document classification systems such as Charles A. Cutter's Expansive Classification (1882) set to classify the world itself and set the field for what has came to be known as authority lists structuring metadata in today's computing.
The structure (summary)[edit]
Facetization of meaning and branching of knowledge are both the domain of the unit of utterance.
While lexicographers[dictionarists] structure thought through multi-layered processes of abstraction of the written record, knowledge growers dissect it into hierarchies of [mutually] contained notions.
One seek to describe the word as a faceted list of small worlds, another to describe the world as a structured lists of words. One play prime in the domain of epistemology, in what is known, controlling the vocabulary, another in the domain of ontology, in what is, controlling reality.
Every [word] has its given things, every thing has its place, closer or further from a single word.
The schism between classifying words and classifying the world implies it is not possible to construct a universal classification scheme[system]. On top of that, any classification system of words is bound to a corpus of texts it is operating upon and any classification system of the world again operates with words which are bound to a vocabulary[lexicon] which is again bound to a corpus [of texts]. It doesn't mean it would prevent people from trying. Classifications function as descriptors of and 'inscriptors' upon the world, imprinting their authority. They operate from [a locus of] their corpus[context]-specificity. The larger the corpus, the more power it has on shaping the world, as far as the word shapes it (yes, I do imply Google here, for which it is a domain to be potentially exploited).
(J) The sequence[edit]
The structure-yielding query [of] the single word [shrinks][zuzuje sa,spresnuje] with preceding and following words. Inquiry proceeds in the flow that establishes another kind[mode] of relationality, chaining words into the sequence. While the structuring property of the query brings words apart from each other, its sequential property establishes continuity and brings these units into an ordered set.
This is what is responsible for attaching textual figures mentioned earlier (lists, schemes, tables) to the body of the text. Associations can be also stated explicitly, by indexing tables and then referring them from a particular point in the text. The same goes for explicit associations made between blocks of the text by means of indexed paragraphs, chapters or pages.
From this follows that all utterances point to the following utterance by the nature of sequential order, and indexing provides means for pointing elsewhere in the document as well.
A lot can be said about references to other texts. Here, to spare time, I would refer you to a talk I gave a few months ago and which is online [10].
This is still the realm of print. What happens with document when it is digitized?
Digitization breaks a document into units of which each is assigned a numbered position in the sequence of the document. From this perspective digitization can be viewed as a total indexation of the document. It is converted into units rendered for machine operations. This sequentiality is made explicit, by means of an underlying index.
Sequences and chains are orders of one dimension. Their one-dimensional ordering allows addressability of each element and [random] access. [Jumps] between [random] addresses are still sequential, processing elements one at a time.
(K) The index[edit]

Summa confessorum [1297-98], 1310. [7]

![[2]](http://en.wikipedia.org/wiki/File:POxy.XX.2260.i-Philitas-highlight.jpeg){kind=link}
[The] sequencing not only weaves words into statements but activates other temporalities, and presents occurrences of words from past statements. As now when I am saying the word utterance, each time there surface contexts in which I have used it earlier.
A long quote from Frederick G. Kilgour, The Evolution of the Book, 1998, pp 76-77:
"A century of invention of various types of indexes and reference tools preceded the advent of the first subject index to a specific book, which occurred in the last years of the thirteenth century. The first subject indexes were "distinctions," collections of "various figurative or symbolic meanings of a noun found in the scriptures" that "are the earliest of all alphabetical tools aside from dictionaries." (Richard and Mary Rouse supply an example: "Horse = Preacher. Job 39: 'Hast thou given the horse strength, or encircled his neck with whinning?')
[Concordance] By the end of the third decade of the thirteenth century Hugh de Saint-Cher had produced the first word concordance. It was a simple word index of the Bible, with every location of each word listed by [its position in the Bible specified by book, chapter, and letter indicating part of the chapter]. Hugh organized several dozen men, assigning to each man an initial letter to search; for example, the man assigned M was to go through the entire Bible, list each word beginning with M and give its location. As it was soon perceived that this original reference work would be even more useful if words were cited in context, a second concordance was produced, with each word in lengthy context, but it proved to be unwieldy. [Soon] a third version was produced, with words in contexts of four to seven words, the model for biblical concordances ever since.
[Subject index] The subject index, also an innovation of the thirteenth century, evolved over the same period as did the concordance. Most of the early topical indexes were designed for writing sermons; some were organized, while others were apparently sequential without any arrangement. By midcentury the entries were in alphabetical order, except for a few in some classified arrangement. Until the end of the century these alphabetical reference works indexed a small group of books. Finally John of Freiburg added an alphabetical subject index to his own book, Summa Confessorum (1297—1298). As the Rouses have put it, 'By the end of the [13]th century the practical utility of the subject index is taken for granted by the literate West, no longer solely as an aid for preachers, but also in the disciplines of theology, philosophy, and both kinds of law.'"
In one sense neither subject-index nor concordane are indexes, they are words or group of words selected according to given criteria from the body of the text, each accompanied with a list of identifiers. These identifiers are elements of an index, whether they represent a page, chapter, column, or other [kind of] block of text. Every identifier is an unique address.
The index is thus an ordering of a sequence by means of associating its elements with a set of symbols, when each element is given unique combination of symbols. Different sizes of sets yield different number of variations. Symbol sets such as an alphabet, arabic numerals, roman numerals, and binary digits have different proportions between the length of a string of symbols and the number of possible variations it can contain. Thus two symbols of English alphabet can store 26^2 various values, of arabic numerals 10^2, of roman numberals 8^2 and of binary digits 2^2.
Indexation is segmentation, a breaking into segments. From as early as the 13th century the index such as that of sections has served as enabler of search. The more [detailed] indexation the more precise search results it enables.
The subject-index and concordance are tables of search results. There is a direct lineage from the 13th-century biblical concordances and the birth of computational linguistic analysis, they were both initiated and realised by priests.
During the World War II, Jesuit Father Roberto Busa began to look for machines for the automation of the linguistic analysis of the 11 million-word Latin corpus of Thomas Aquinas and related authors.
Working on his Ph.D. thesis on the concept of praesens in Aquinas he realised two things:
"I realized first that a philological and lexicographical inquiry into the verbal system of an author has t o precede and prepare for a doctrinal interpretation of his works. Each writer expresses his conceptual system in and through his verbal system, with the consequence that the reader who masters this verbal system, using his own conceptual system, has to get an insight into the writer's conceptual system. The reader should not simply attach t o the words he reads the significance they have in his mind, but should try t o find out what significance they had in the writer's mind. Second, I realized that all functional or grammatical words (which in my mind are not 'empty' at all but philosophically rich) manifest the deepest logic of being which generates the basic structures of human discourse. It is .this basic logic that allows the transfer from what the words mean today t o what they meant to the writer.
In the works of every philosopher there are two philosophies: the one which he consciously intends to express and the one he actually uses to express it. The structure of each sentence implies in itself some philosophical assumptions and truths. In this light, one can legitimately criticize a philosopher only when these two philosophies are in contradiction." [11]
Collaborating with the IBM in New York from 1949, the work, a concordance of all the words of Thomas Aquinas, was finally published in the 1970s in 56 printed volumes (a version is online since 2005 [12]). Besides that, an electronic lexicon for automatic lemmatization of Latin words was created by a team of ten priests in the scope of two years (in two phases: grouping all the forms of an inflected word under their lemma, and coding the morphological categories of each form and lemma), containing 150,000 forms [13]. Father Busa has been dubbed the father of humanities computing and recently also of digital humanities.
The subject-index has a crucial role in the printed book. It is the only means for search the book offers. Subjects composing an index can be selected according to a classification scheme (specific to a field of an inquiry), for example as elements of a certain degree (with a given minimum number of subclasses).
Its role seemingly vanishes in the digital text. But it can be easily transformed. Besides serving as a table of pre-searched results the subject-index also gives a distinct idea about content of the book. Two patterns give us a clue: numbers of occurrences of selected words give subjects weights, while words that seem specific to the book outweights other even if they don't occur very often. A selection of these words then serves as a descriptor of the whole text, and can be thought of as a specific kind of 'tags'.
This process was formalized in a mathematical function in the 1970s, thanks to a formula by Karen Spärck Jones which she entitled 'inverse document frequency' (IDF), or in other words, "term specificity". It is measured as a proportion of texts in the corpus where the word appears at least once to the total number of texts. When multiplied by the frequency of the word in the text (divided by the maximum frequency of any word in the text), we get term frequency-inverse document frequency (tf-idf). In this way we can get an automated list of subjects which are particular in the text when compared to a group of texts.
We came to learn it by practice of searching the web. It is a mechanism not dissimilar to thought process involved in retrieving particular information online. And search engines have it built in their indexing algorithms as well.
There is a paper proposing attaching words generated by tf-idf to the hyperlinks when referring websites [14]. This would enable finding the referred content even after the link is dead. Hyperlinks in references in the paper use this feature and it can be easily tested: [15].
There is another measure, cosine similarity, which takes tf-idf further and can be applied for clustering texts according to similarities in their specificity. This might be interesting as a feature for digital libraries, or even a way of organising library bottom-up into novel categories, new discourses could emerge. Or as an aid for researchers to sort through texts, or even for editors as an aid in producing interesting anthologies.
Final remarks[edit]
- 1
New disciplines emerge all the time - most recently, for example, cultural techniques, software studies, or media archaeology. It takes years, even decades, before they gain dedicated shelves in libraries or a category in interlibrary digital repositories. Not that it matters that much. They are not only sites of academic opportunities but, firstly, frameworks of new perspectives of looking at the world, new domains of knowledge. From the perspective of researcher the partaking in a discipline involves negotiating its vocabulary, classifications, corpus, reference field, and specific terms[subjects]. Creating new fields involves all that, and more. Even when one goes against all disciplines.
- 2
Google can still surprise us.
- 3
Knowledge has been in the making for millenia. There have been (abstract) mechanisms established that govern its conditions. We now possess specialized corpora of texts which are interesting enough to serve as a ground to discuss and experiment with dictionaries, classifications, indexes, and tools for references retrieval. These all belong to the poetic devices of knowledge-making.
- 4
Command-line example of tf-idf and concordance in 3 steps.
- 1. Process the files text.1-5.txt and produce freq.1-5.txt with lists of (nonlemmatized) words (in respective texts), ordered by frequency:
for i in {1..5}; do tr '[A-Z]' '[a-z]' < text.$i.txt | tr -c '[a-z]' '[\012*]' | tr -d '[:punct:]' | sort | uniq -c | sort -k 1nr | sed '1,1d' > temp.txt; max=$(awk -vvar=1 -F" " 'NR==1 {print $var}' temp.txt); awk -vmaxx=$max -F' ' '{printf "%-7.7f %s\n", $1=0.5+($1/(maxx*2)), $2}' <temp.txt > freq.$i.txt; done && rm temp.txt
- 2. Process the files freq.1-5.txt and produce tfidf.1-5.txt containing a list of words (out of 500 most frequent in respective lists), ordered by weight (specificity for each text):
for j in {1..5}; do rm freq.$j.txt.temp; lines=$(wc -l freq.$j.txt) && for i in {1..500}; do word=$(awk -vline="$i" -vfield=2 -F" " 'NR==line {print $field}' freq.$j.txt); tf=$(awk -vline="$i" -vfield=1 -F" " 'NR==line {print $field}' freq.$j.txt); count=$(egrep -lw $word freq.?.txt | wc -l); idf=$(echo "1+l(5/$count)" | bc -l); tfidf=$(echo $tf*$idf | bc); echo $word $tfidf >> freq.$j.txt.temp; done; sort -k 2nr < freq.$j.txt.temp > tfidf.$j.txt; done
- 3. Process the files tfidf.1-5.txt and their source text, text.txt, and produce occ.txt with concordance of top 3 words from each of them:
rm occ.txt && for j in {1..5}; do echo "$j" >> occ.txt; ptx -f -w 150 text.txt.$j > occ.$j.txt; for i in {1..3}; do word=$(awk -vline="$i" -vfield=1 -F" " 'NR==line {print $field}' tfidf.$j.txt); egrep -i "alpha: $word" occ.$j.txt >> occ.txt; done; done
Dušan Barok
Written 23 October - 1 November 2014 in Bratislava and Stuttgart.